
Customer Support & Helpdesk
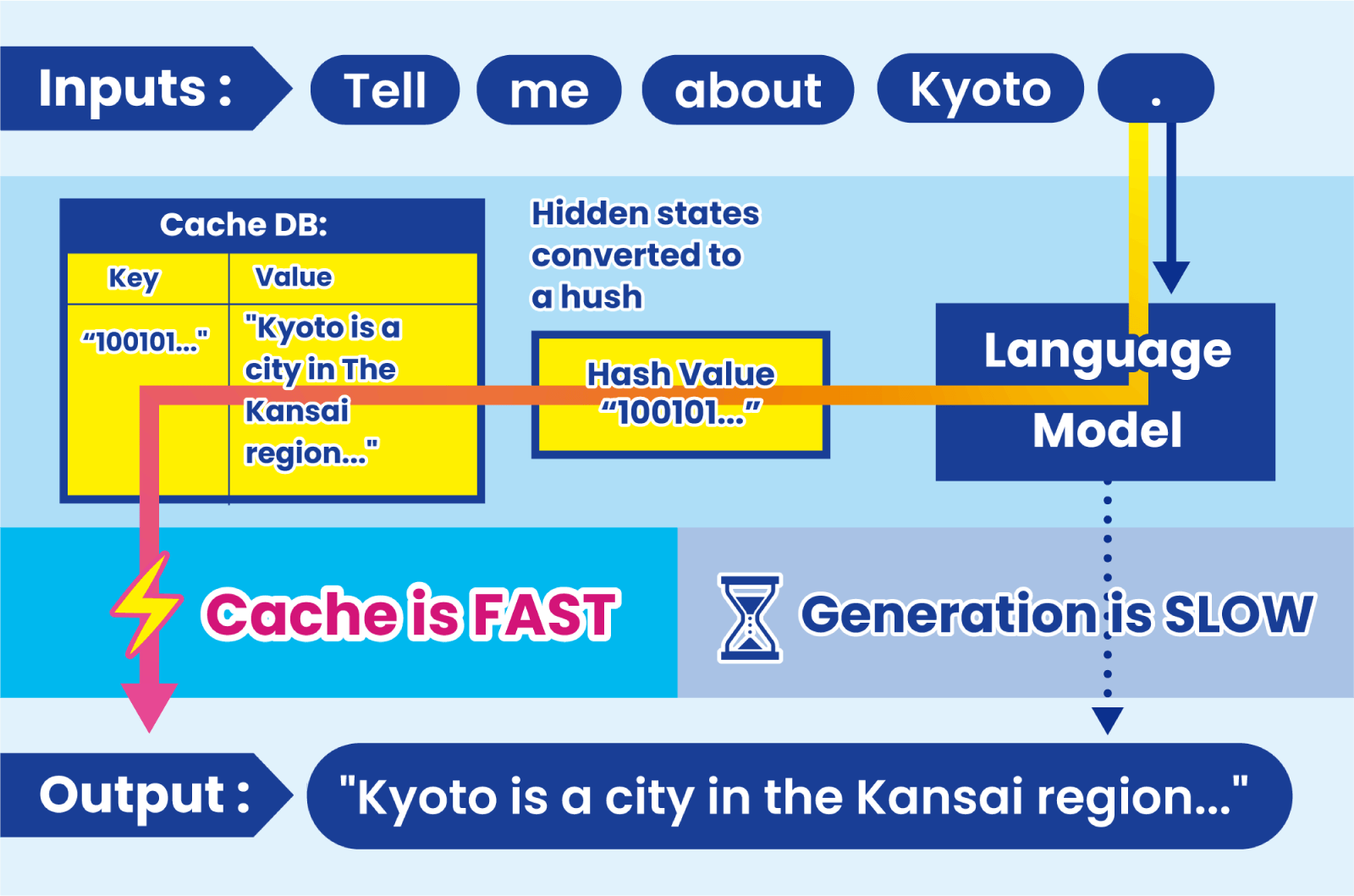
Reduce repeated LLM computation across similar support queries.
High cache hit rates in ticket classification, response drafting, and knowledge-grounded Q&A significantly lower cost and latency.
Why this works: Support workflows naturally contain recurring semantic patterns.